A Significant Moment
In my view, the release of LLAMA3 marks a highly significant moment, especially with its 8B model that surpasses the capabilities of 3.5, yet with a smaller model size, sparking endless possibilities and imagination.
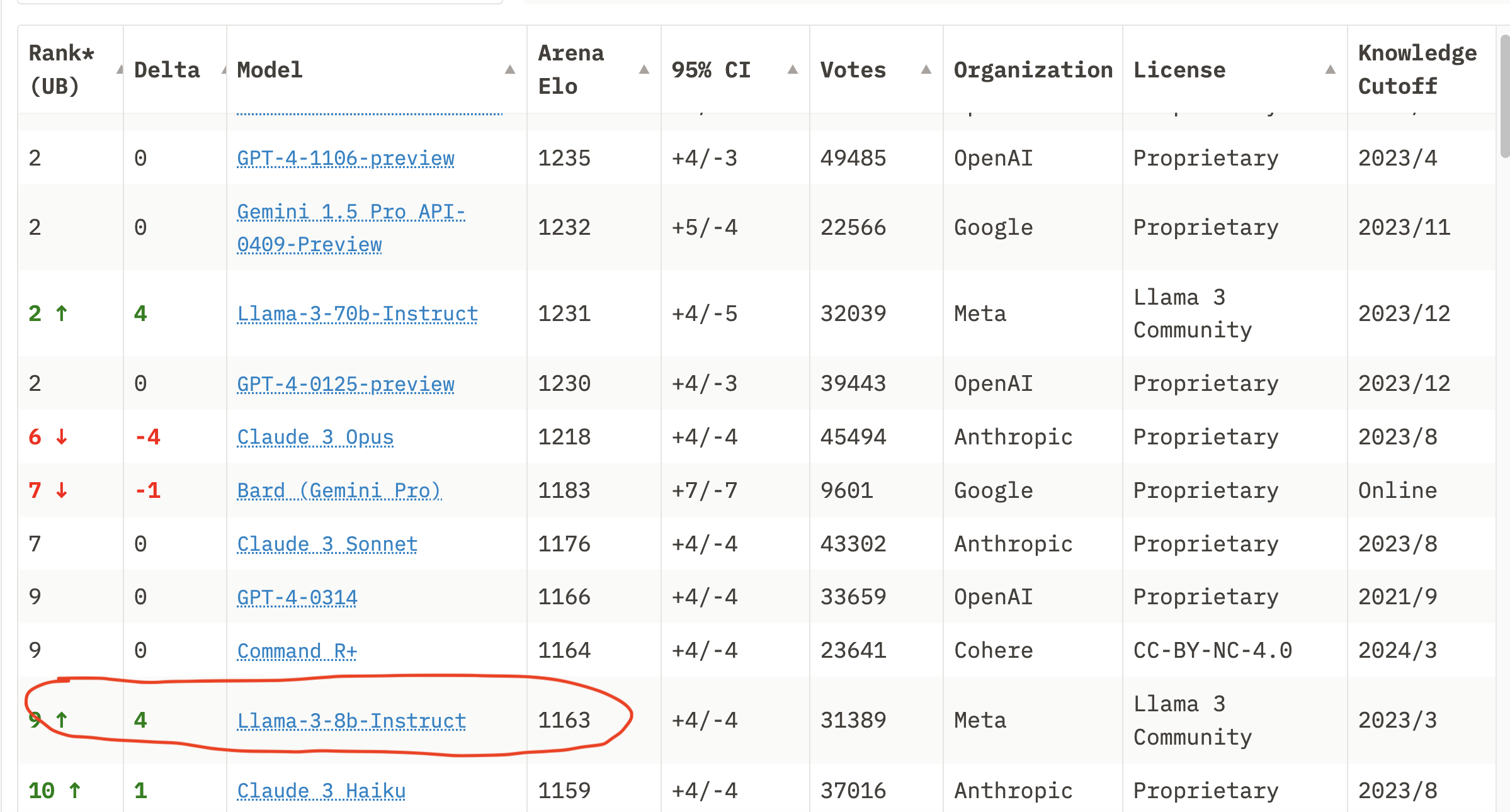
You don't need to look for GPT-3.5 in this chart anymore; its ranking has dropped to over 20th place.
Two Significant Changes
The release of LLAMA3 has brought about two major changes:
-
A drastic reduction in fine-tuning costs, allowing anyone to fine-tune LLAMA3 at a lower cost, thus unleashing community creativity.
-
Due to its smaller model size, there's a decrease in inference costs, leading to two possibilities:
a. Extreme inference speeds, such as achieving astonishing speeds with Groq.
b. Localized on-device model usage, providing a good experience on personal computers and usability on mobile devices.
As expected, just two weeks after LLAMA3's release, the community has seen a surge of interesting use cases.
Diverse Fine-Tune Models in Full Bloom
Firstly, there are various fine-tune models to consider. Let's take a look at the number of LLAMA3 fine-tune models on Hugging Face. As of now, just two weeks after LLAMA3's release, there are already over 5000 fine-tune models available, highlighting the vibrant activity within the community.
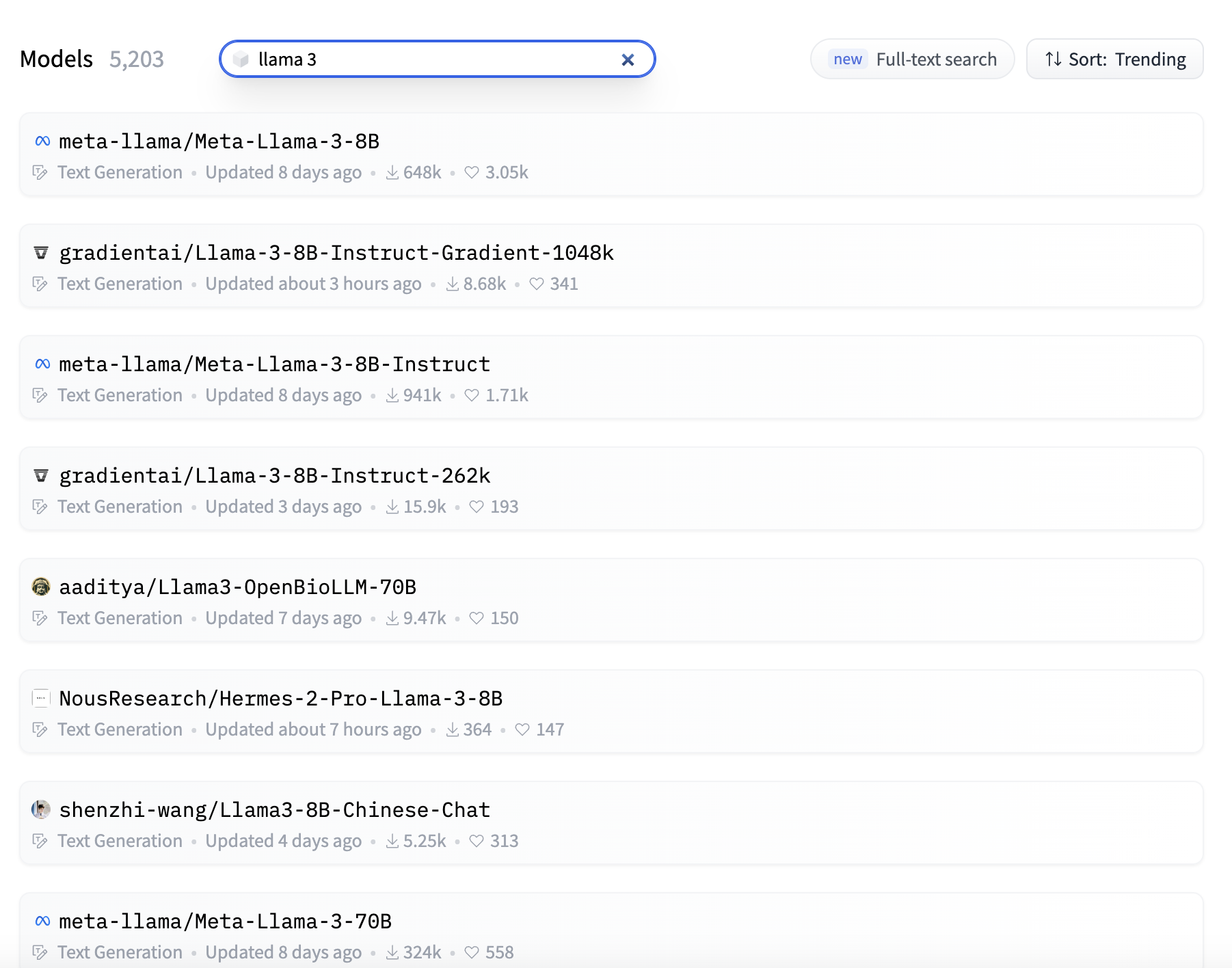
Exploring LLAMA3 Community Fine-Tune Creativity
Let's explore the interesting creativity that LLAMA3 community fine-tuning has brought us from several dimensions.
Long Text Capabilities, Reaching 1M Context
Long text capabilities have always been a hot pursuit for major models. In this aspect, the first release was the 8B model using the POSE scheme, which elevated the model to 256K context llama-3-8b-256k-PoSE. This already surpasses the limits of many current models. However, the innovation doesn't stop there. GradientAI swiftly released the 8B model Llama-3-8B-Instruct-Gradient-1048k, offering a 1M context, directly targeting the core selling point of Google Gemini's 1M context capability.
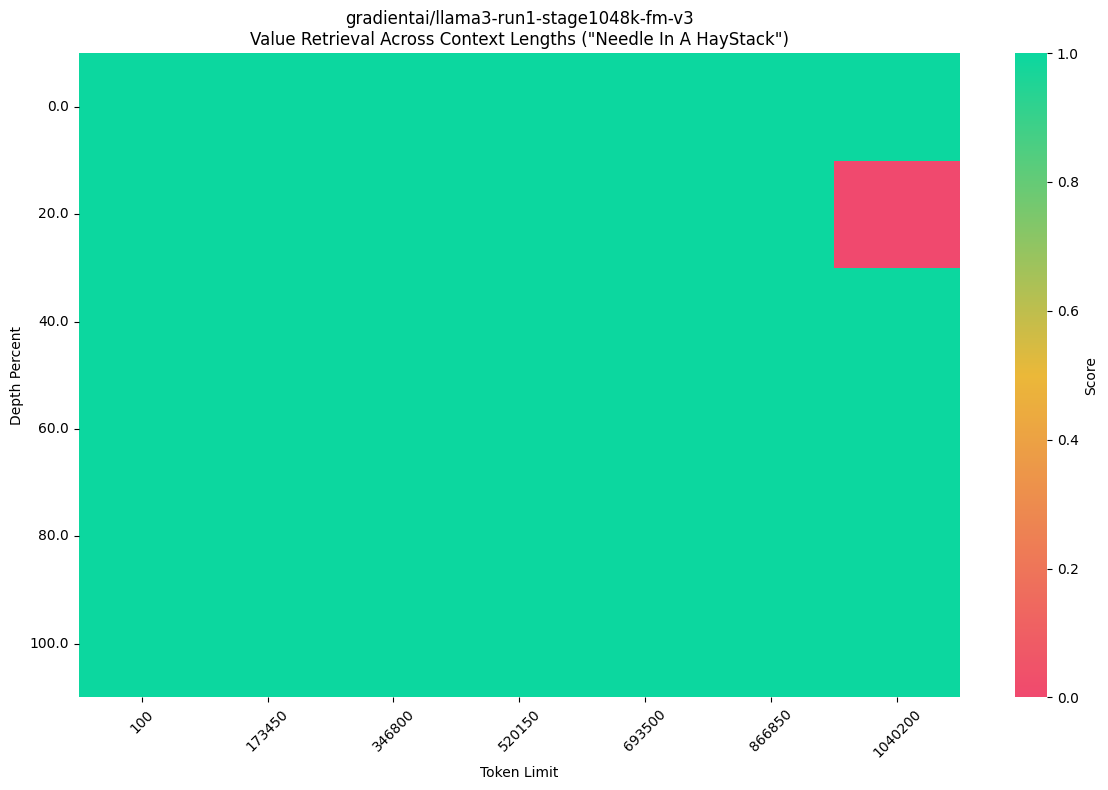
Not only has the community fine-tuned long context on the 8B model, but also on the 70B model. AbacusAI fine-tuned the Llama-3-Giraffe-70B model to support 128K context, also utilizing the POSE scheme to expand the context.
However, while large models can support ultra-long contexts, their ability to effectively extract useful information from such lengthy contexts (the needle in the haystack problem) is crucial. Currently, there's no conclusive evidence from tests indicating their proficiency in this area; further testing is required.
Visual Capabilities - Vision Models
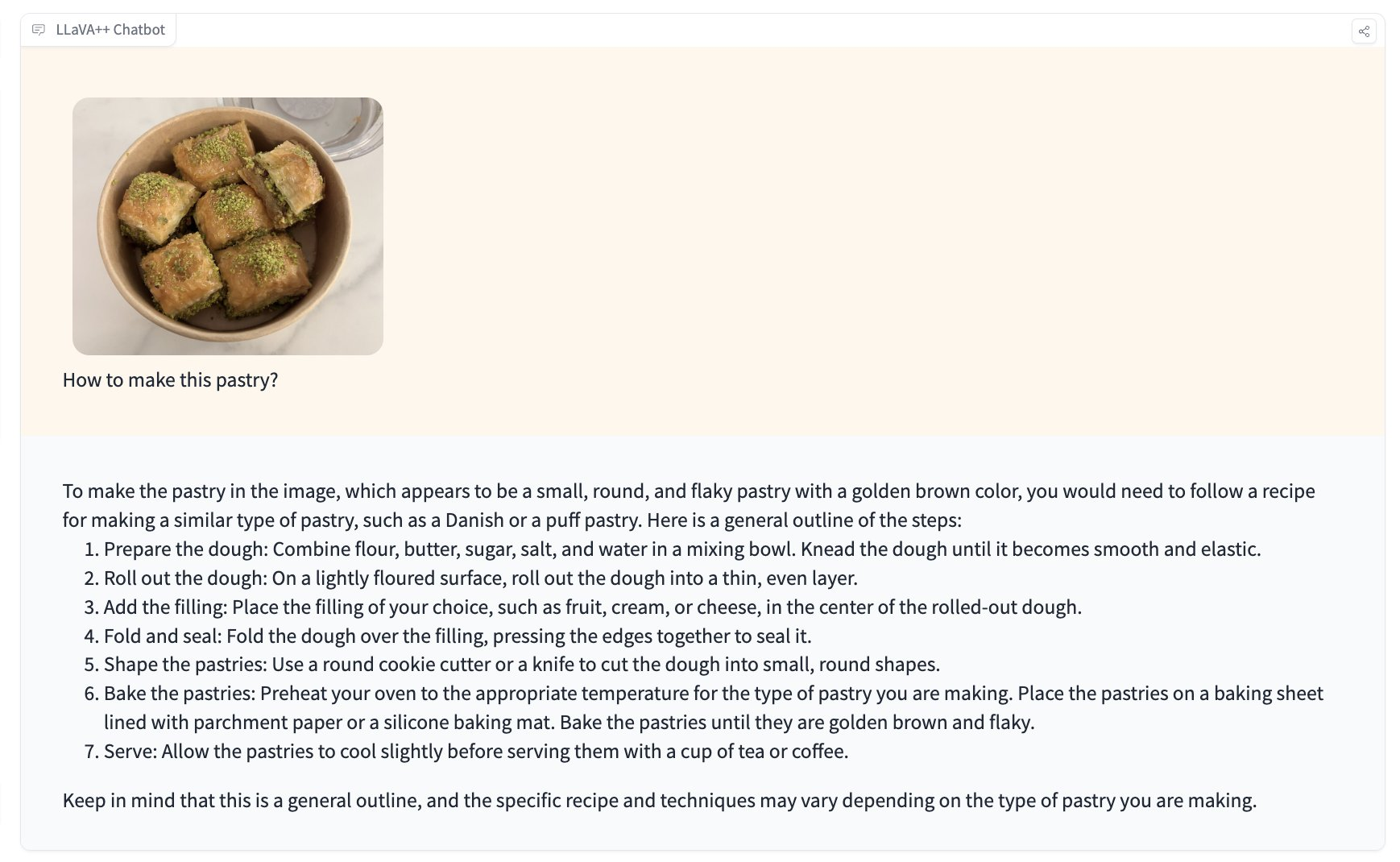
The release of GPT4-vision has been astonishing due to its profound visual understanding capabilities. Now, based on LLAMA3, vision models have also emerged. Here is a demonstration of the effectiveness of the LLaVA-Meta-Llama-3-8B-Instruct model, which combines LLaVA v1.5 and LLAMA3 8B training, possessing good inference abilities. This fusion of LLAMA3 8B as a part of multimodal capabilities is expected to empower LLAMA3 further in the future. Similar vision models include Bunny-Llama-3-8B-V and others.
Task-Specific Models
For example, there are models fine-tuned specifically for function calling, such as llama-3-8B-Instruct-function-calling. Function calling is a crucial aspect of implementing agents, and if this capability is significantly improved, it can greatly enhance the overall effectiveness of the agent.
There are also other models designed for various specialized tasks, but I won't list them all here.
Furthermore, some models in the community aim to enhance the overall capabilities of LLAMA3 by fine-tuning its abilities with high-quality data.
Model Capability Enhancement
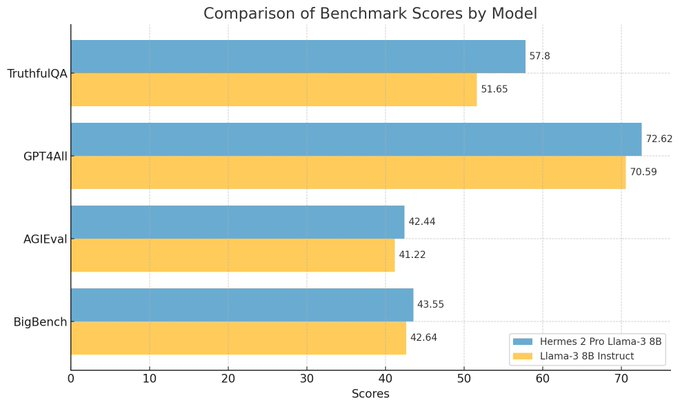
For instance, Hermes-2-Pro-Llama-3-8B exhibits remarkable conversational abilities, supports function calling and JSON data returns, and surpasses official llama-3 8B instruct models in various test metrics.
Language-Specific Enhancement
There are also models designed to enhance specific languages. The original Chinese capabilities of LLAMA3 8B were not very strong, so the community has developed many models fine-tuned using high-quality Chinese data. An example of this is Llama3-8B-Chinese-Chat.

Besides models enhanced for Chinese, there are also models tailored for Japanese, such as suzume-llama-3-8B-japanese and others.
Triggering the Fine-Tune Tool Boom
With the increasing demand for fine-tuning, a plethora of tools for fine-tuning have emerged within the community.
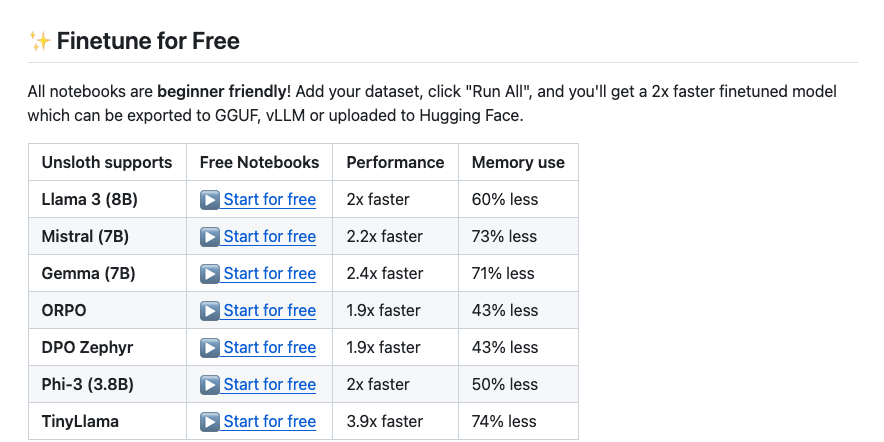
1. unsloth
unsloth provides a direct Colab link for fine-tuning, requiring just a click to run and a short wait to complete training. unsloth can achieve fine-tuning on LLAMA in a shorter time and with less GPU memory, undoubtedly enhancing the originally low-cost fine-tuning of LLAMA 3 8B. unsloth supports both 4-bit and 16-bit quantization.
2. Fine-Tuning MLX-LM on Mac
Mac users face challenges in using large models due to the lack of support for Nvidia graphics cards. However, with the introduction of the MLX framework by Mac, fine-tuning LLAMA3 8B becomes possible. Using MLX-LM, fine-tuning LLAMA3 only requires a few simple steps.
3. Fine-Tuning Platform
Platforms like https://monsterapi.ai/ allow even those with no coding experience to fine-tune models. Simply upload your data to complete the model fine-tuning process.
Having discussed fine-tuning, let's now explore some changes on the inference side.
Inference Speed
When it comes to inference speed, one of the most memorable solutions is Groq. It utilizes specialized inference hardware to accelerate model inference.
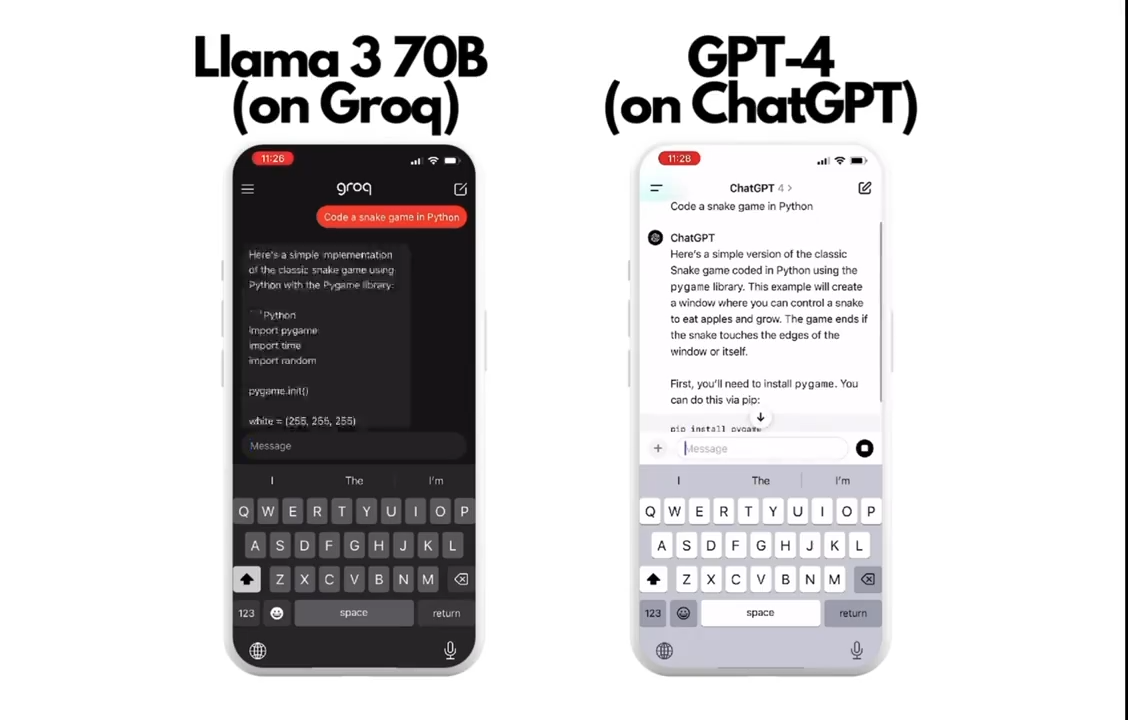
LLAMA3 itself has a relatively fast inference speed due to its smaller model size, and when combined with specific LPU acceleration, inference on Groq achieves remarkable speeds. For instance, LLAMA3 70B on Groq can reach 284 tokens/s, while LLAMA3 8B can reach 876 tokens/s.
There's a fascinating video comparison where LLAMA3 70B and GPT4 perform a coding task on Groq. LLAMA3 on Groq completes the task instantly, while GPT4 is still coding slowly.
Application on the Edge
Due to its small size, LLAMA3 8B can be used on personal computers and even mobile devices.
Efficient Use of LLAMA on Personal Computers
Many tools have emerged in the community that makes it convenient to use LLAMA on personal computers, such as LM Studio and ollama. These tools make it very easy to perform LLAMA3 inference on personal computers.
Behind these tools is the excellent llama.cpp project, which optimizes inference for various systems and is rewritten in C. Its support for the gguf format has become a popular choice for fine-tuning models in the community. It can be said that most LLAMA inference tools on personal computers are based on the encapsulation of llama.cpp.
Usable on Mobile Devices
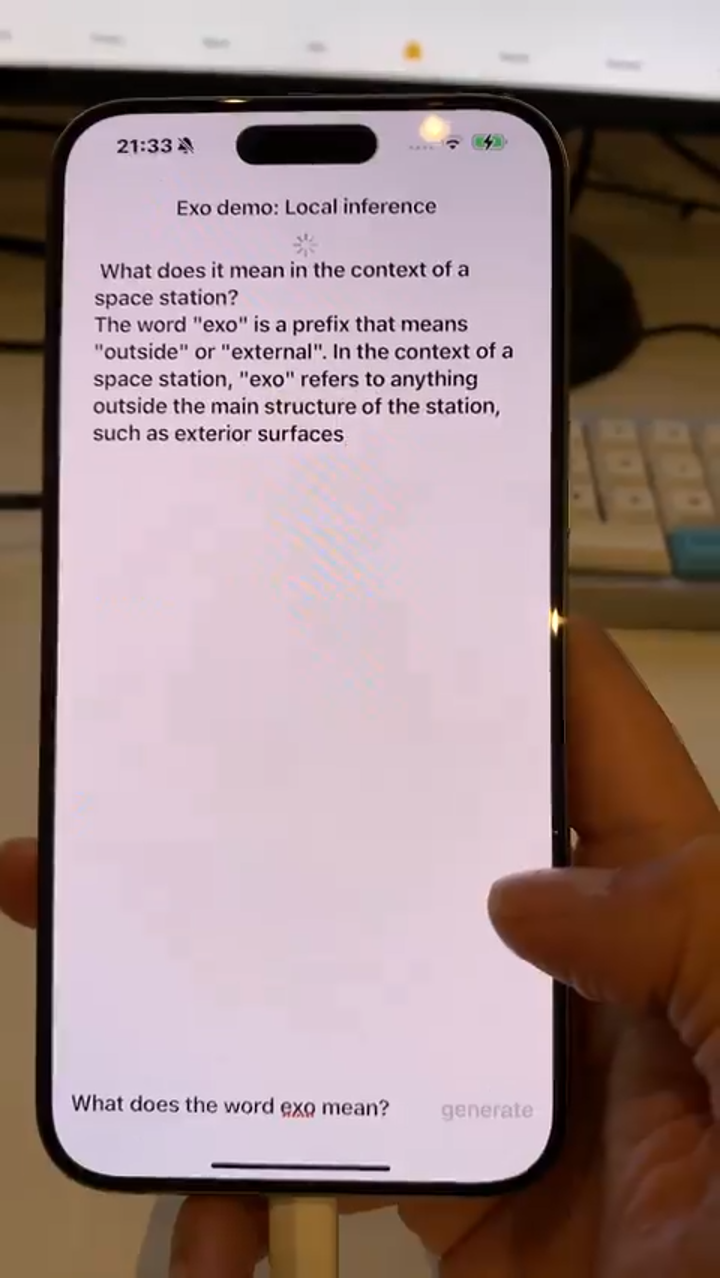
I've always believed that edge models only can run on personal computers is not a significant enough change. In the mobile era, the usage of mobile devices far exceeds that of personal computers, making the ability to run large models on mobile devices a crucial moment. LLAMA3-8B can achieve this.
For example, some community members use models like Meta-Llama-3-8B-Instruct-4bit, a 4-bit quantized model converted into Apple-optimized mlx format, to run smoothly on iPhones.
Interesting Applications
The community has seen a plethora of interesting LLAMA3 applications:
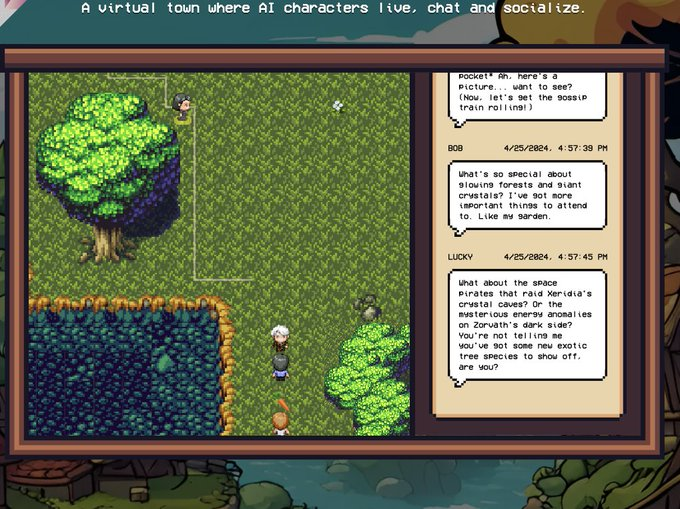
Local LLAMA3-Powered AI Town
For example, the previously popular AI town is now completely powered by local LLAMA3.
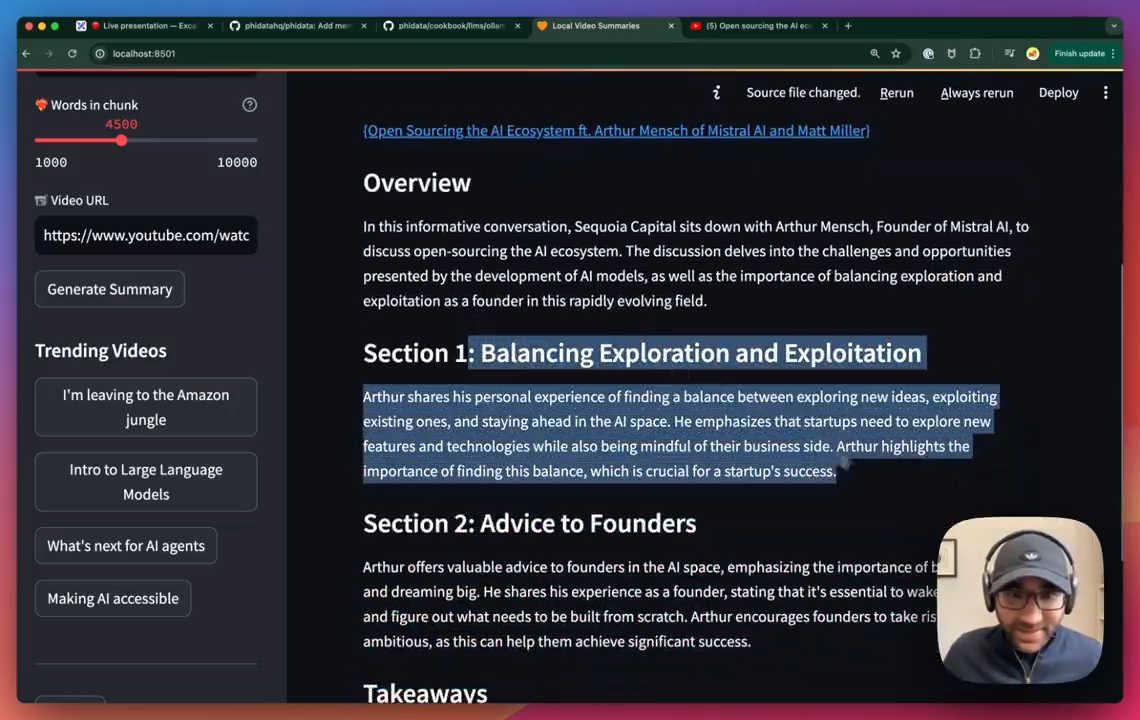
Using LLAMA Locally for Video Summarization
Using ollama locally with LLAMA3, you can segment longer videos and automatically generate summaries.
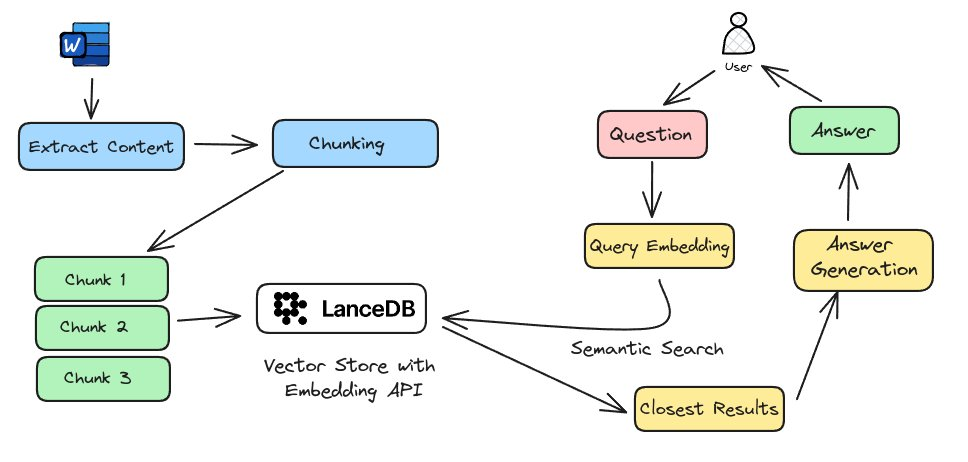
Building a Local RAG System with LLAMA
By extracting content, recursively segmenting, embedding chunks, semantic searching, and ultimately passing it through the standard RAG process using LLAMA3, a local RAG system has been developed. This was accomplished conveniently using tools like ollama.
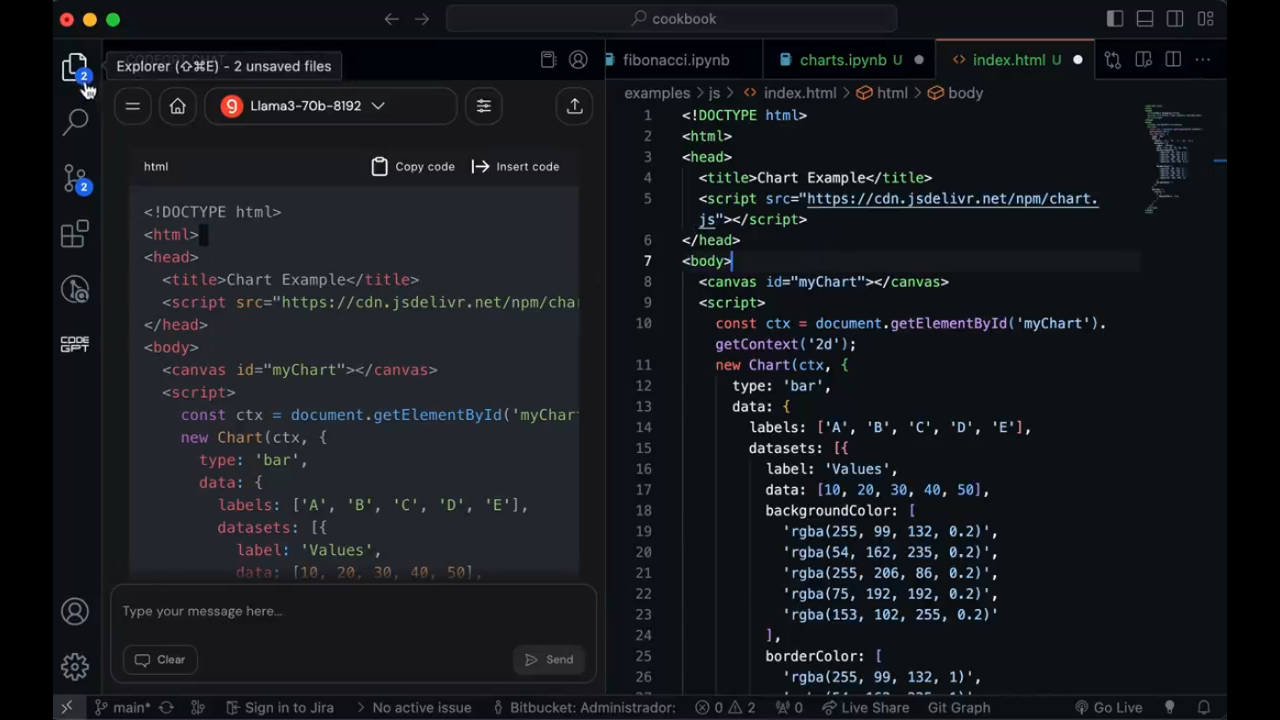
Setting Up vscode Copilot
Leveraging Groq's ultra-fast inference speed with LLAMA3, combined with the Code-GPT plugin, it's entirely possible to create your own vscode Copilot.
Conclusion
From the theoretical prediction of a community Boom after LLAMA3's release to witnessing the continuous enthusiasm in the community over the next two weeks, LLAMA3 has brought us many surprises. While we anticipate the emergence of more parameter-efficient and powerful models in the future, LLAMA3 marks an important beginning. Its low-cost fine-tuning has facilitated community creativity, leading to the development of new models that further fuel the prosperity of the application ecosystem.
Additionally, the improvement of localized models is making them increasingly user-friendly, reducing the cost of large models and meeting the demand for offline model usage. We look forward to a future where mobile devices can provide an excellent user experience with large models, similar to what we currently experience on personal computers. It's an inspiring future!
If you're interested in LLAMA or LLM, feel free to contact me to collaborate on building a thriving LLAMA ecosystem.